موضوعی که قراره درباره اش صحبت بکنم رو شرکتهای بزرگی در ایران به داشتن این دانش و مهارت نیاز دارند و اگه دوست دارید کار دیتا بکنین احتمالا به اونها نیاز دارید و این که چیزهایی هستن که احتمالا تو ارشد یادمیگیرن ولی دونستنشون خیلی میتونه به پیشرفتتون تو این زمینه کمک کنه. امیدوام بتونم یه دید کلی بهتون در زمینه big data بدم.

تو این پست من ابتدا یه مقدمهای میگم در مورد این که مسئلمون چیه و در ادامه دو قسمت که مربوط به batch processing و stream processing هست رو توضیح میدم.
در اولین قسمت مسئلمون رو بیان میکنیم:
تعریف مسئله:
زمانی که شما یه سیستم نرم افزاری راه میاندازید به تدریج ورودی سیستم شما داده ایجاد میکند. با افزایش کاربرانتون این حجم از داده افزایش می باید تا جایی که ما از آن تحت عنوان big data یاد میکنیم یعنی داده ای که نتوان آن را روی یک سیستم ذخیره کرد یا این که نتوان پردازش آن را روی یک سیستم انجام داد.
اکثر شرکت ها از این داده استفاده میکنند تا این که سرویسی رو به کاربرانشون بدن یا این که تحلیلی روی بر اساس رفتار و دادههای کاربران در جهت بهترکردن سیستمشون انجام بدن. در هر دوحالت ما نیازمند مکانیزم هایی برای پردازش داده های کلان هستیم. به همین جهت موضوعمون به دو قسمت تقسیم میشه:
1- پردازش داده به صورت دسته ای: که در این حالت داده ها موجودند و قرار است روی آن ها پردازش انجام شود و در حالت دوم2- پردازش جریان داده: که در این حالت داده به صورت real time وارد سیستم میشود و همان زمان باید روی آن پردازش انجام شود.گاهی تنها مورد اول رو تحت عنوان big data بیان میکنند که این اشتباه است. و در این مقاله میخوایم این دو مفهوم که تکمیل کننده یک سیستم big data هستند رو بررسی کنیم و ابزارها و کاربردهای اون رو بیان کنیم.
داده های حجیم:
من اینجا سه تا مثال از سه تا شرکت معروف واستون اوردم که یه دیدی نسبت پیدا کنیم به این که وقتی میگیم این شرکت ها پردازش داده حجیم انجام میدن این داده در چه مقیاسی هست.
یوتیوب حدود 4 میلیون مشاهده در دقیقه داره
آدما توی توییتر در هر دقیقه حدود 450 هزار تا توییت میکنن.
و آدما توی اینستاگرام حدود 46 هزار پست در دقیقه قرار میدن.

توسعه اینچنین سیستم هایی نیازمند stream processing و batch processing هستند تا بتونند به این میزان از کاربران سرویس بدن
در قسمت اول میریم سراغ batch processing یا پردازش داده به صورت دسته ای. در این حالت فرض بر این است که داده در پایگاه داده موجود بوده و بر اساس نیاز کاربر نیاز است روی این حجم از داده پردازش شوند. داده های موجود نیز حجیم بود و بر روی چندین سرور قرار دارد.
برای این کار گوگل یک مدل برنامه نویسی تحت عنوان نگاه کاهش یا map reduce ارائه داد.
ایدهشون هم خیلی ساده است. این که پردازش روی داده ها روی هر سرور به صورت جداگانه روی داده ای که در اختیار دارد انجام شود و در نهایت نتیجه این ها به گونه ای تجمیع شده و نتیجه پردازش جواب داده شود.
بخواهیم این ایده رو دقیق تر بیان میکنیم.
ابتدا داده ای تحت عنوان داده حجیم روی سیستم توزیع شده ای در اختیار داریم.
داده ها تحت توابع به اسم map function پردازش میشوند . نتیجه آن ها به گونه ای جابه جا میشود تا پردازش های که تجمیع آن ها در یک خروجی دارد در کنار هم قرار گیرند و در نهایت با استفاده از تابع reduce این نتایج تجمیع شوند و به عنوان خروجی پردازش محاسبه شوند.
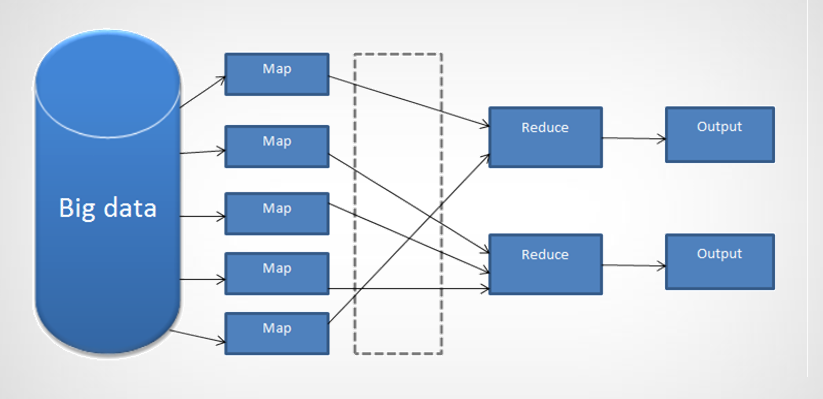
برای این که بهتر مفهوم بشه این مدل یک مثال معروف رو بیان میکنم.
فرض کنیم قراره تعداد هر یک از کلمات موجودی که در پایگاه داده هامون قرار دارند رو بشمریم. ممکنه که هر کلمه روی چند تا سرور قرار داشته باشه.
در مرحله اول همونجوری که میبیید این دیتا ها روی چند تا سرور قرار گرفته شده اند.
تابع map function تعداد هر کلمه روی هر سرور رو میشماره و تحت یک key value اونا رو واسه خروجی مرحله بعد آماده میکنه و که key در این جا همون کلمه و value آن تعدادی است از آن کلمه که در آن سرور موجود است.
در مرحله بعد سرور دیگری همه این key value ها را گرفته و آن ها را shuffle میکند تا key های مشابه در کنار هم قرار گفته و برای مرحله بعد که reduce است آماده شوند.
در مرحله بعد keyهای یکسان reduce پیدا میکنند که تابعی است که تعداد را جمع میزند. و در نهایت جواب مسئله آماده است.
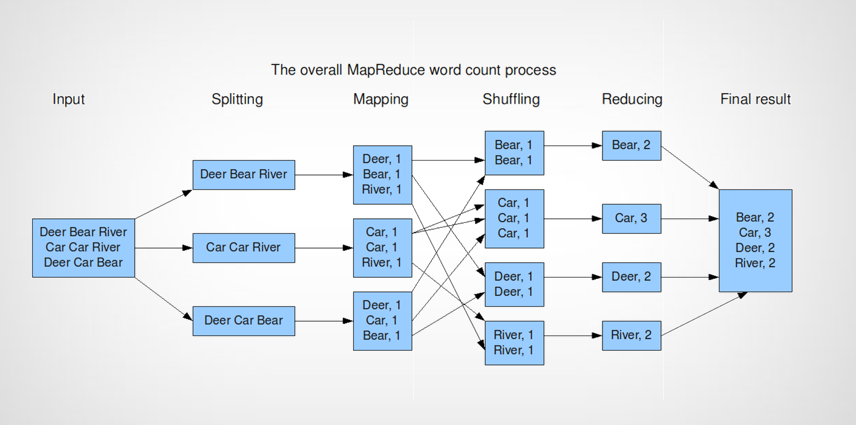
تا الان ما یک مدل برنامه نویسی رو ارائه کردیم. که شاید در عمل اگر بخواهیم آن را پیاده سازی کنیم سخت به نظر برسد.
Hadoop و Spark
برای این کار گوگل frameworkای تحت عنوان هدوپ ارائه داد که فایل سیستم ای که برای این کار نیاز است و interface ای که تحت آن کاربر میتواند توابع map و reduce خود را تعریف کند را توسعه داد. با استفاده از hadoop به راحتی میشود function های map و reduce را تعریف کرد و به راحتی میتوان دیتا در قالب فایل سیستم تعریف شده اضافه کرد.
فایل سیستم hdfs رو اگه بخوایم دقیق تر واردش بشیم از دو قسمت اصلی data node و name node تشکیل شدند که data node ها وظیفه ذخیره کردن داده و name node وظیفه اضافه کردن سرور مانیتور کردن سرورها و ایجاد چندین کپی از داده ها برای جلوگیری از failure و به طور کلی وظیفه مدیریت را بر عهده دارد.

مشکلی که هدوپ داشت این بود که برای پردازش داده ها داده ها باید ابتدا از دیسک خوانده میشدند که این از نظر زمان هزینه بر است.
در ادامه ابزاری تحت عنوان اسپارک توسعه داده شد که کار رو خیلی راحت تر کرد.
اسپارک روی هدوپ توسعه داده شد با این قابلیت که پردازش ها به صورت سریع تر و in-meomory انجام میشدند. اسپارک همچنان از مدل map reduce پشتیبانی میکند با این تفاوت که داده آن به صورت data frame است و کار را برای برنامه نویس بسیار راحت تر میکند زیرا برنامه نویسی مشابه قبل دیتا را به صورت یکی جدول میبیند بدون این که نیاز داشته باشد بداند چگونه به صورت in-memory در اسپارک این حجم از داده پردازش میشود.
قابلیت اسپاک لایبرری هایی است که در اختیار قرار داده است که پردازش هایی مانند یادگیری ماشین با اکثر الگوریتم های پیاده سازی شده مانند clustering و classification انجام میشود.
به راحتی متیوان تحت عنوان sql روی داده ها query زد.
و میتوان الگوریتم هایی که نیاز به پردازش گرافی دارند را به راحتی استفاده کرد.

در اینجا میرسیم به بخش دوم که پردازش جریان داده یا stream processing است.
Stream processing
تا اینجا فرض بر این بود که داده حجیم رو در اختیار داریم و قراره بر روی اون پردازش انجام بدیم ولی این مدل کافی نیست.
ما سیستمهایی داریم که نیازه ورودی اون ها داده در حجم زیاده و نیازه پردازش همون لحظه روی اون ها انجام بشه. به دو دلیل این که کاربر همون لحظه به اون جواب نیاز داره و این که داده پس از مدتی دیگه ارزشی نداره.
جریان داده هم هیچ گاه قطع نمیشه بنابراین ما حتی نمیتونیم اون حجم از داده رو ذخیره کنیم و اصلا در آینده ارزشی هم برای ذخیره کردن ندارد.
بنابراین ما به مدل برنامه نویسی نیاز داریم تا در این حالت ورودی سیستم که حجیم است را نیز پردازش کند.
کاربردهایی مانند ایجاد پایپ لاین برای پردازش داده و تشخیص الگو روی داده های ورودی دارد.

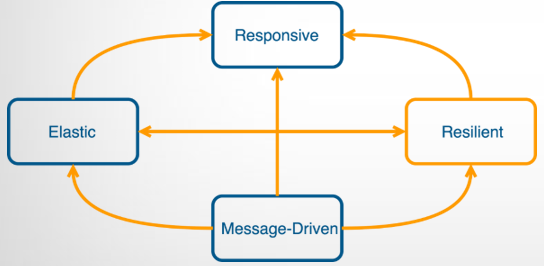
چنین سیستم هایی برای این که بتوانند همیشه برای کاربر با این حجم از داده در دسترس باشند تحت عنوان سیستم های reactive شناخته میشوند.
این سیستم ها 4 ویژگی رو باید برآورده میکنند که برای برآورده کردن اون ها ما نیاز به سیستم های توزیع پذیر داریم.
یک زمان پاسخ آن ها باید سریع باشند که تحت عنوان responsive بیان میشود.
دومین ویژگی تحت عنوان resilient بیان میکند که باید خطاهای سیستم را به صورت خودکار برطرف کند تا ویژگی اول تضمین شود.
سه elastic باشد تا بر اساس میزان باری که بر روی پردازه است تنظیم شود.
و چهارم این که message driven باشد تا بتوان از قابلیت برنامه نویسی همروند استفاده کرد.
ما برای این که بتوانیم پردازش ها را به صورت stream پردازش کنیم نیازداریم تا چنین سیستم هایی به صورت توزیع شده طراحی کنیم.
همروندی:
قبل از این که مدلمون رو برای ایجاد چنین سیستم هایی پیشنهاد بدیم نیازه تا قبلش مشخص کنیم به چه همروندی نیاز داریم. طبق اون چیزی که توی سیستم عامل خوندیم همروندی رو میتونیم با استفاده از thread و مفاهیمی مانند semaphore به کار ببریم ولی این نوع برنامه نویسی مشکلاتی از قبیل deadlock دارد که کار را برای برنامه نویس سخت میکند و نمیتوان از قابلیت سیستم های توزیع شده به راحتی استفاده کرد.
دومین روش همروندی استفاده از message passingاست که threadها تحت عنوان message با همدیگه ارتباط برقرار میکنند.
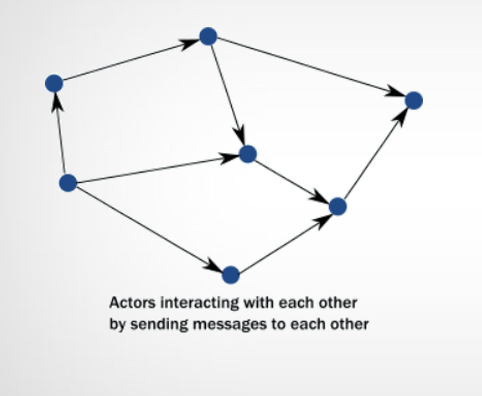
Actor model
همون طور که در شکل میبینید هر actor که یک thread است تحت عنوان یک object شناخته میشود. و actorها با استفاده از message با همدیگه ارتباط برقرار میکنند. این نوع مدل برنامه نویسی به شدت همروندی را ایجاد میکند و با استفاده از آن میتوان سیستم های reactiveای ساخت که داده های حجیم را پردازش کند.
ایده ای actor model ایده ی قدیمیه ولی ابزارهایی امروزی اش به شدت این نوع مدل برنامه نویسی رو راحت کرده به عنوان مثال در زبان اسکالا فریمورکی به نام akka وجود دارد که به راحتی در آن یک actor میتواند به یک actor در یک cluster دیگر پیام بفرستد و به راحتی میتوان با استفاده از آن پایپ لاین داده ایجاد کرد با این قابلیت که خود آن میزان ورود و خروج پیام ها به اکتورها را کنترل میکند تا سیستم به علت پردازش زیاد از کار نیفتد.
Actor model یه مدل برنامه نویسی رو ارائه داد که به خصوص برای زبان های functional بسیار کاربردیه. اگه یه قدم تو ابزارهایی که داریم بخوایم جلوتر بریم ابزار کافکا رو معرفی میکنیم.
این ابزار توسط linkedin توسعه داده شده و این امکان رو در اختیار ما قرار میده که پیام هایی که تحت مدل actor مدل در سیستم تولید میشود را در این سیستم وارد کنیم. پیام ها در این سیستم publish یا فرستاده شده و actorهای دیگری این پیام ها را consume میکنند.
این ابزار به راحتی میتواند روی چندین سیستم توزیع شود تا بتوان حجم زیادی از پیام ها را توسط actor ها مختلف پردازش کرد.

جمع بندی :
تا این جا ما دو حالت پردازش داده های کلان که به صورت batch و stream بودند رو بررسی کردیم.
ابزارهای اونا که شامل Hadoop و spark واسه قسمت اول و actor model و kafka که واسه قسمت دوم بودن رو بررسی کردیم.
امیدوارم تونسته باشم یه دید کلی بهتون بدم از این که big data و سیستم های توزیع شده چی هستند و اگه علاقه مند هستید به کار دیتا تونسته باشم مسیری رو بهتون نشون داده باشم.
منابع مفید
https://medium.freecodecamp.org/a-thorough-introduction-to-distributed-systems-3b91562c9b3c
https://github.com/onurakpolat/awesome-bigdata
https://github.com/theanalyst/awesome-distributed-systems
https://github.com/rShetty/awesome-distr کتاب soft skills برای software developerها
درباره این سایت